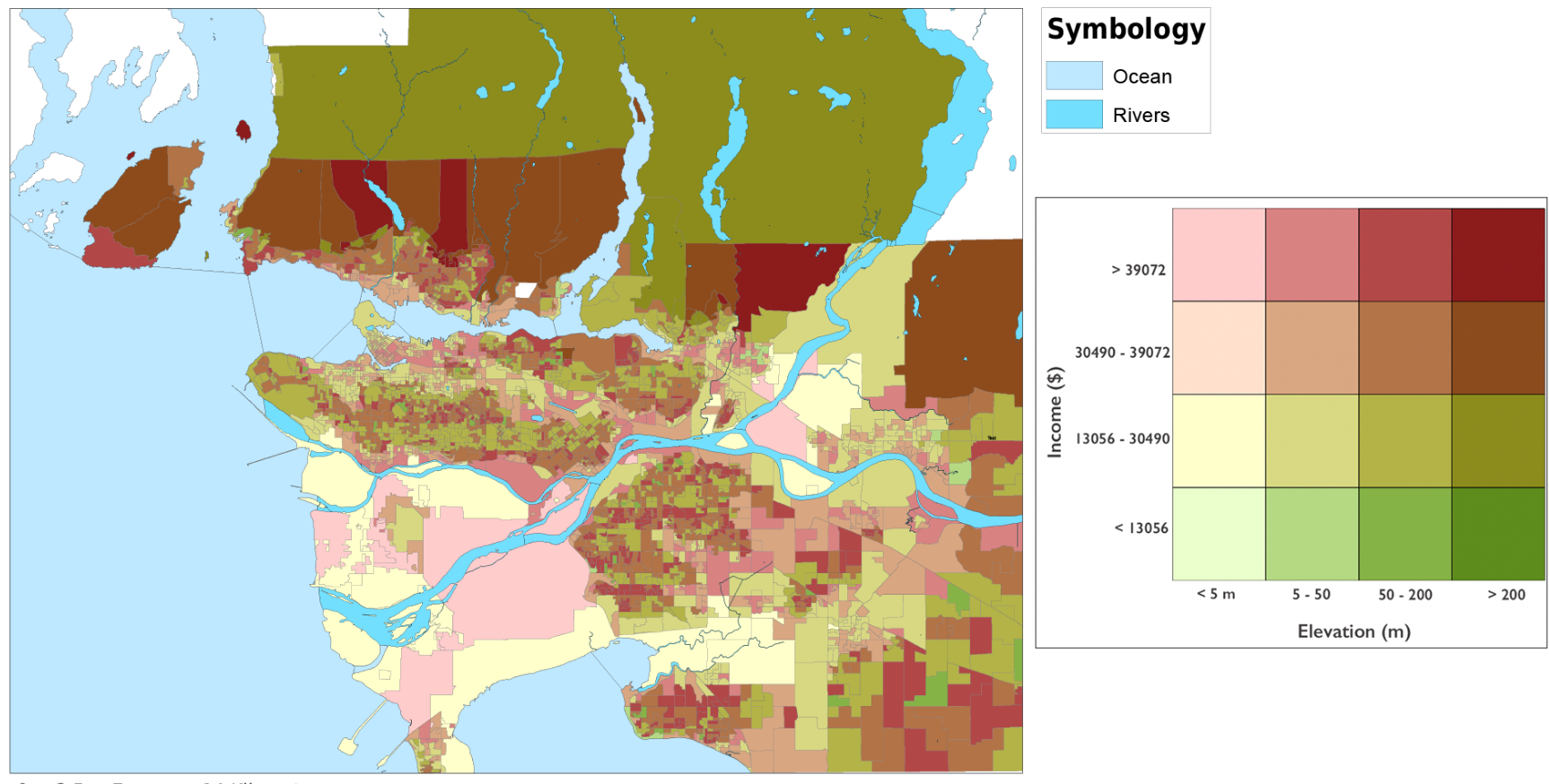
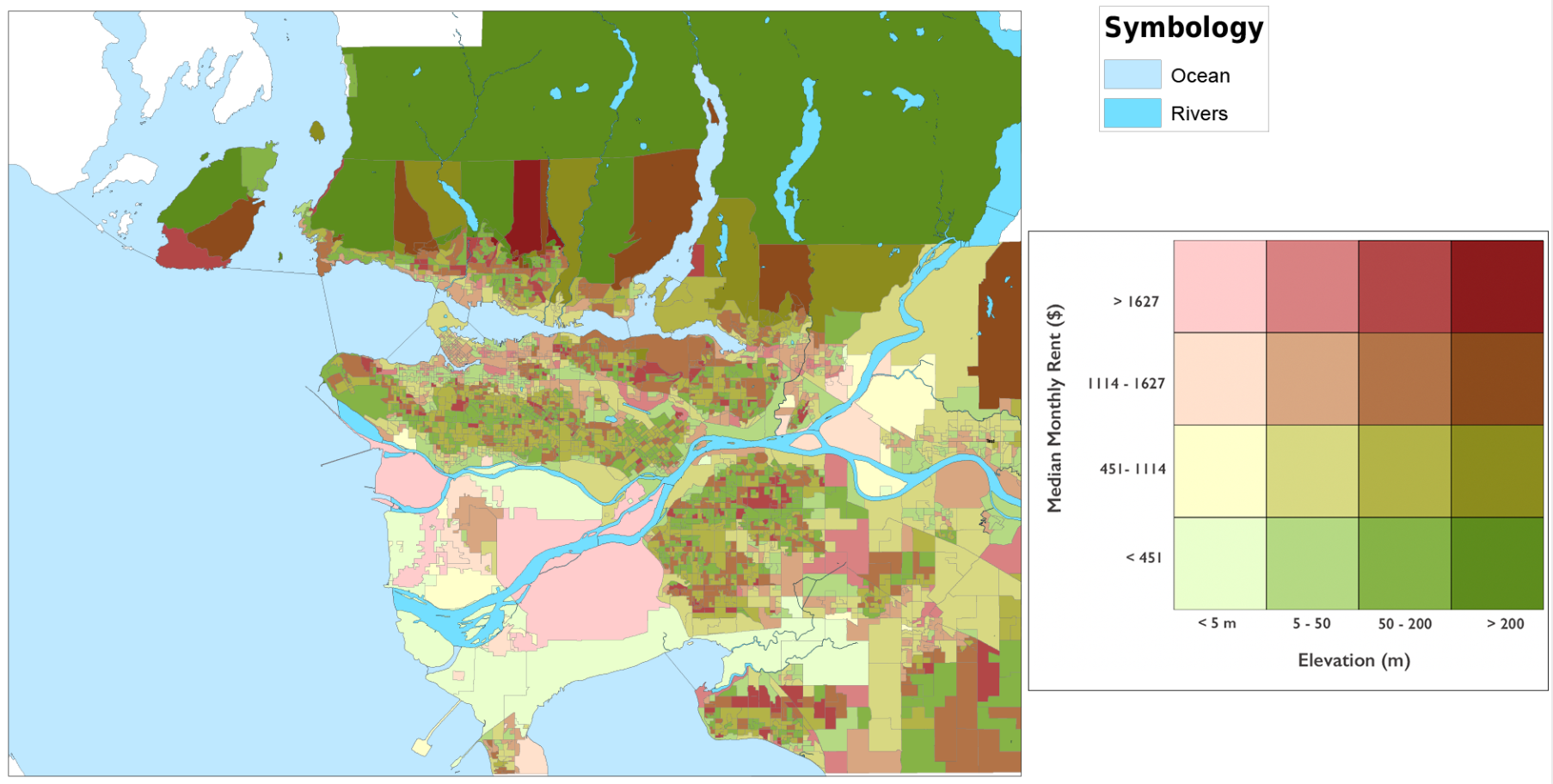
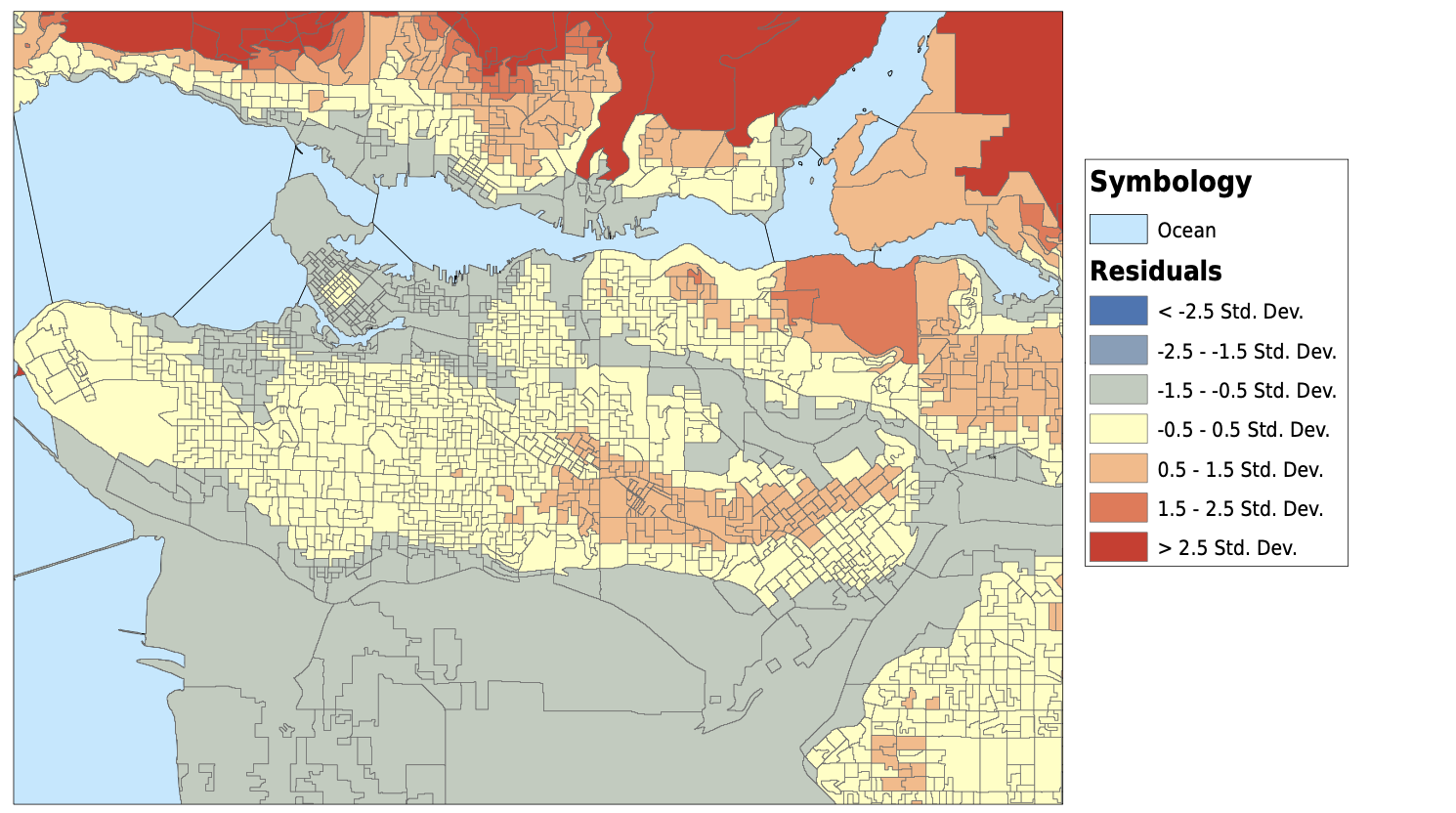
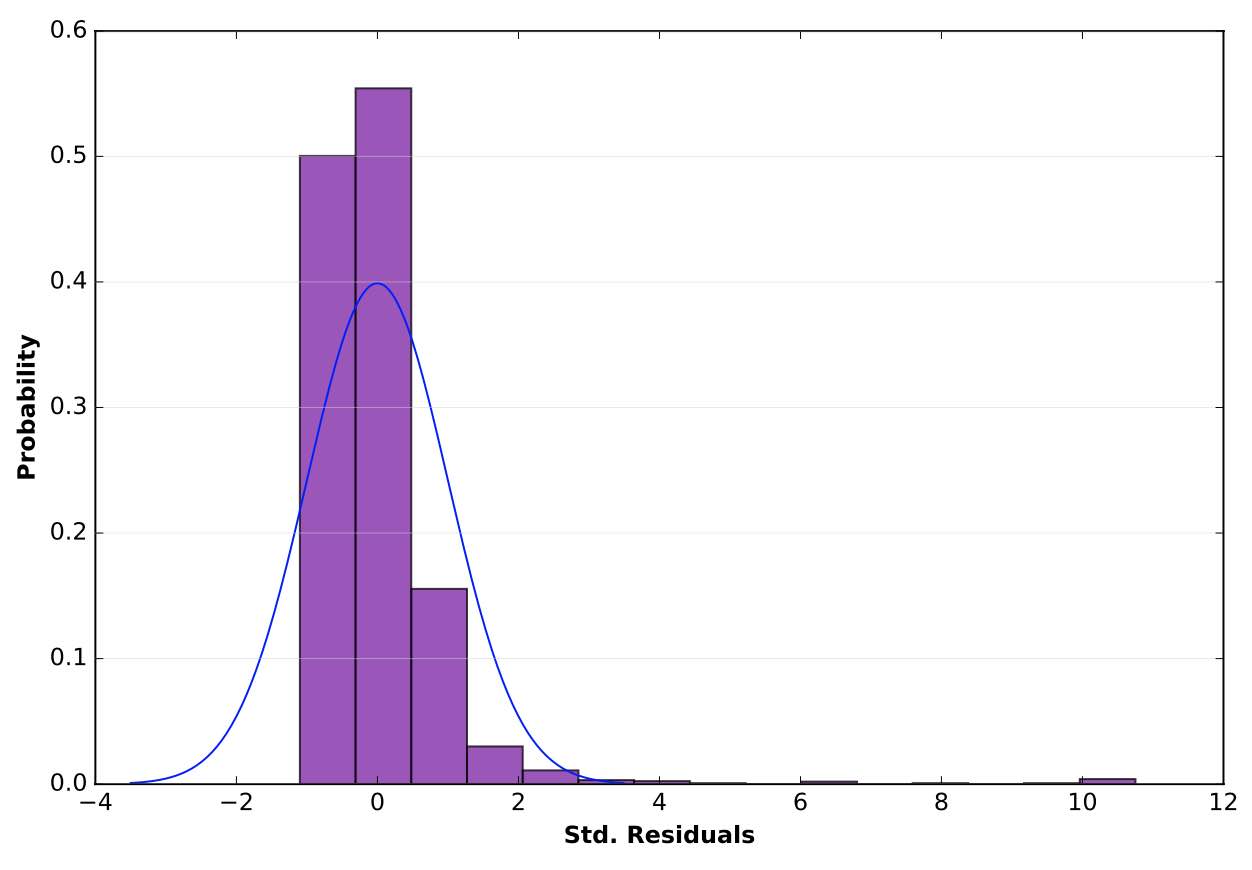
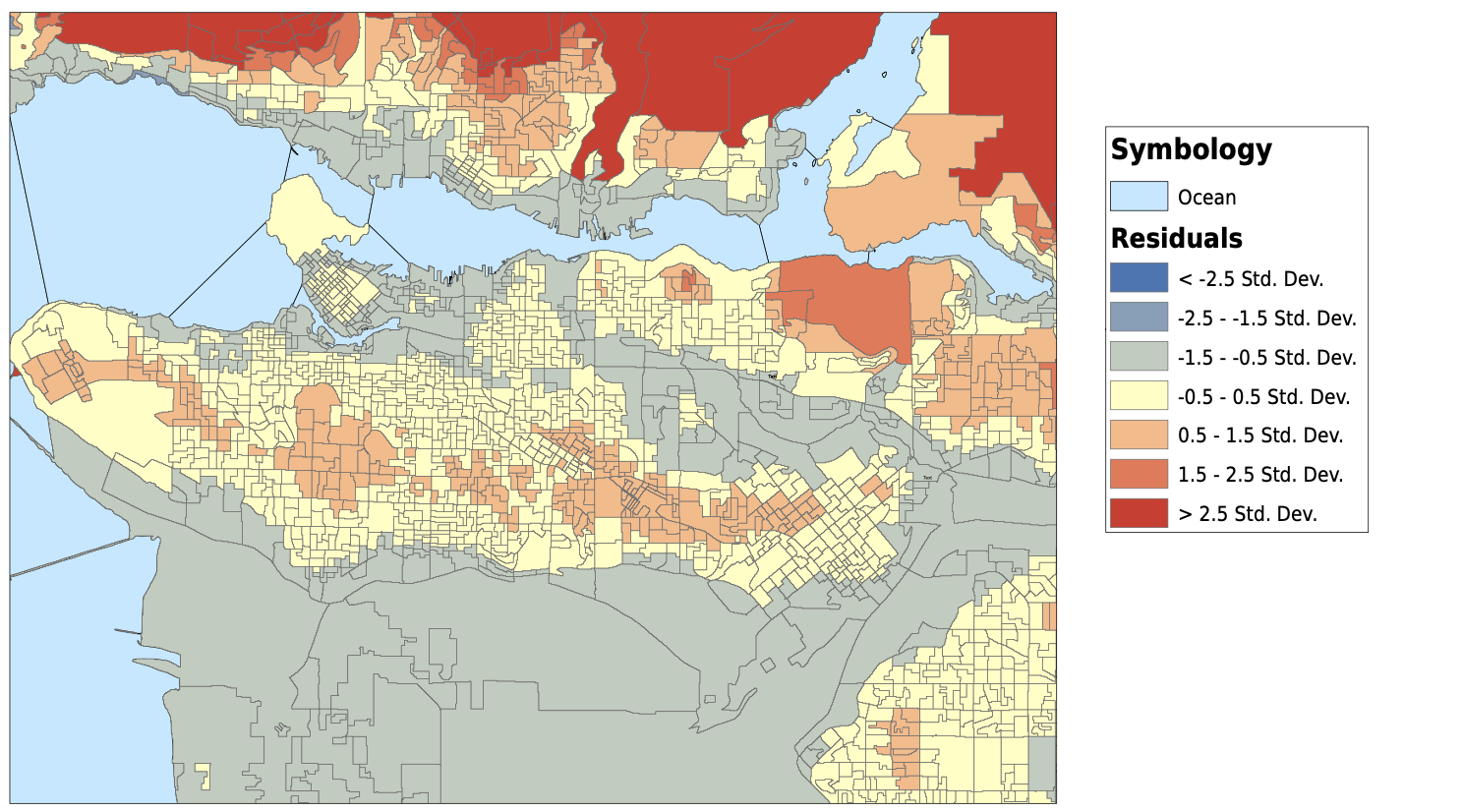
Bivariate Choropleth Map
These maps are the result of my bivariate choropleth analysis. After classifying each variable into four classes, selecting 16 different pairs of attributes for each map, and typing in the correlating RGB colour scheme, I came up with these. The left is median income and elevation, and the right is median monthly rental cost and elevation. At first glance, it looks like there could be some clusters of similar colours. The areas with a low income/monthly rent and a low elevation are coloured pale green and yellow. We can see the palest colour mainly in Richmond, and sprinkled in a few other places around the city. It is also possible to see a low elevation and a slightly higher rent/income in many places around Vancouver. This map shows that there could be a relationship between where we see low elevations, and low income/rent. However, this alone is not conclusive. This pattern could be random and this map could be demonstrating a lack of a relationship between these variables. The bivariate choropleth analysis is not enough on its own to determine a spatial relationship.